Context:
In a pioneering paper entitled ‘Attention Is All You Need’, a team at Google proposed transformers — a deep neural network architecture that has today gained popularity across all modalities.
About Machine Learning (ML):
- It is a subfield of artificial intelligence that teaches computers to solve tasks based on structured data, language, audio, or images, by providing examples of inputs and the desired outputs.
- For example:
-
- In text, classifying a document as scientific or literary may be solved by counting the number of times certain words appear.
- In audio, spoken text is recognised by converting the audio into a time frequency representation.
- In images, a car may be found by checking for the existence of specific car like edge shaped patterns.
What is a Deep Neural Network?
- Deep learning neural networks, or artificial neural networks, attempts to mimic the human brain through a combination of data inputs, weights, and bias
- These are the neural networks that attempt to simulate the behaviour of the human brain—albeit far from matching its ability—allowing it to “learn” from large amounts of data
- It consists of multiple nodes that are little parts of the system, and they are like neurons of the human brain.
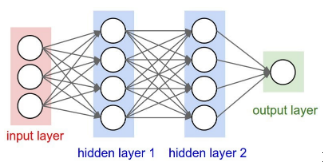
Fig: Deep neural network
- When a stimulus hits them, a process takes place in these nodes. Some of them are connected and marked, and some are not, but in general, nodes are grouped into layers.
- The system must process layers of data between the input and output to solve a task.
- The more layers it has to process to get the result, the deeper the network is considered.
- DNNs ingest a complete document or image and generate a final output, without the need to specify a particular way of extracting features.
What is a Transformer?
- A transformer is a two part neural network.
- The first part is an ‘encoder’ that ingests the input sentence in the source language (example- English) and the second part is a ‘decoder’ that generates the translated sentence in the target language (example- Hindi).
- The encoder converts each word in the source sentence to an abstract numerical form that captures the meaning of the word within the context of the sentence, and stores it in a memory bank.
- The decoder generates one word at a time referring to what has been generated so far and by looking back at the memory bank to find the appropriate word.
- Both these processes use a mechanism called attention.
- Improvement: A key improvement over previous methods is the ability of a transformer to translate long sentences or paragraphs correctly. The adoption of transformers subsequently exploded. The capital ‘T’ in ChatGPT, for example, stands for ‘transformer’.
- Use in computer vision:
-
- Transformers have also become popular in computer vision as they simply cut an image into small square patches and line them up, just like words in a sentence.
- Today, transformer models constitute the best approach for image classification, object detection and segmentation, action recognition, and a host of other tasks.
- Transformers’ ability to ingest anything has been exploited to create joint vision and language models which allow users to search for an image (eg, Google Image Search), describe one, and even answer questions regarding the image.
- Concerns related to the transformers:
-
- The scientific community is yet to figure out how to evaluate these models rigorously.
- There are also instances of “hallucination”, whereby models make confident but wrong claims.
- There is an urgent need to address societal concerns, such as data privacy and attribution to creative work, that arise as a result of their use.
What is ‘attention’?
- Attention in ML allows a model to learn how much importance should be given to different inputs.
- Usage in translation: Attention allows the model to select or weigh words from the memory bank when deciding which word to generate next.
- Usage in image description: Attention allows models to look at the relevant parts of the image when generating the next word.
- Transformers feature several attention layers both within the encoder, to provide meaningful context across the input sentence or image, and from the decoder to the encoder when generating a translated sentence or describing an image.
News Source: The Hindu


 16 May 2023
16 May 2023






 GS Foundation
GS Foundation Crash Course
Crash Course Combo
Combo Optional Courses
Optional Courses Degree Program
Degree Program







